Entropy
This is based on @brereton-2022. First we count the number of observations in each grid. Then we have
where is the proportion of observation in grid , is the number of observations in grid , and finally is the total number of observations.
The entropy is then
- Note that we use Base 10 log, originally entropy is base 2, but the behaviourists seem to use 10,
- we define , and
- This lies between 0 and
If all the observations lie in one grid then we have
If the data is evenly spread, then
So we have
For a empirical p-value for entropy - see ?@sec-entropy-pv.
Modified spread of participation index (SPI)
From @plowman-2003, we have
where
- is the number of zones,
- is the observed frequency in zone ,
- is the expected frequency in zone ,
- is the total number of observations:
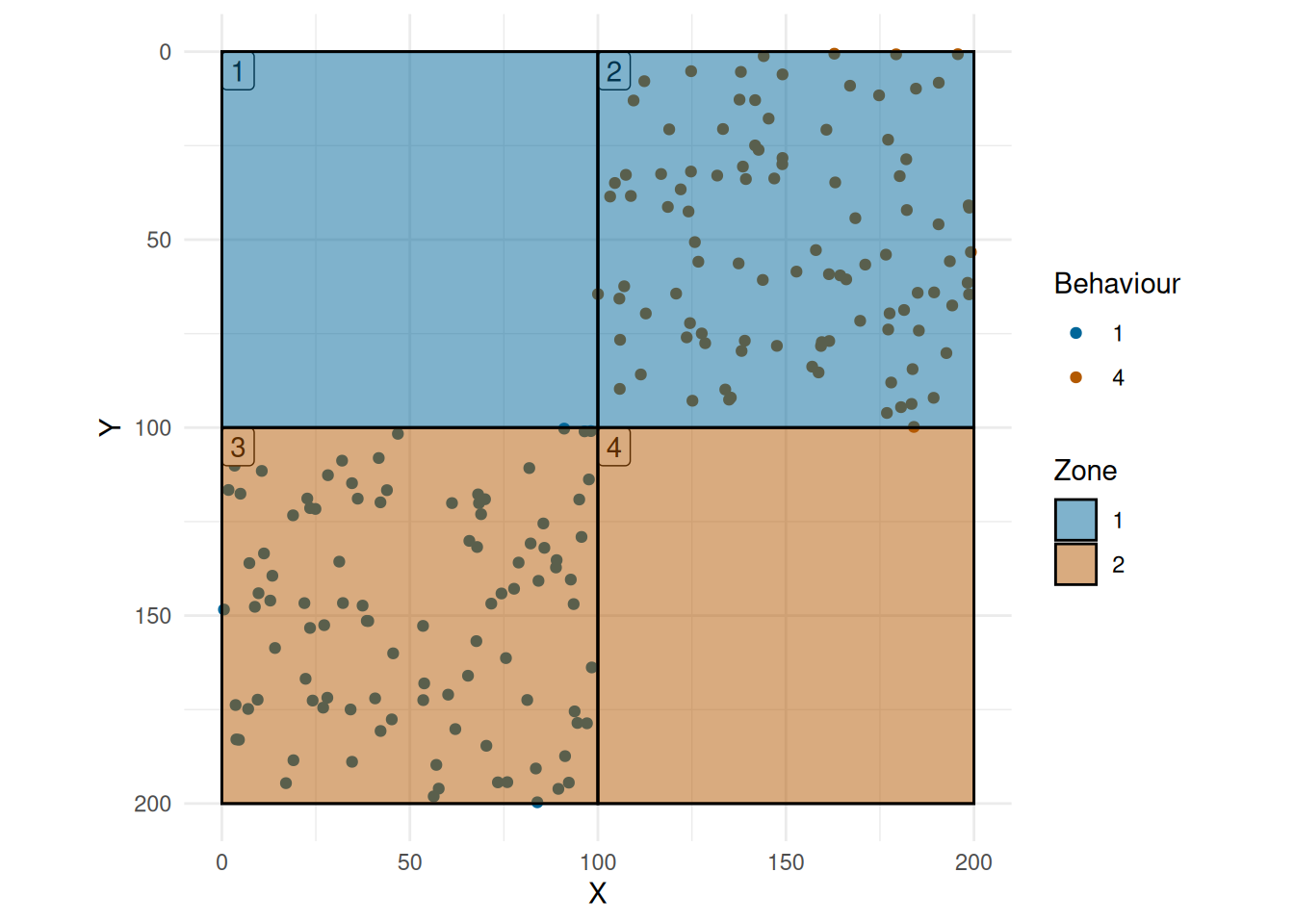
For even spread, we should have a SPI of zero. To test this, consider the simulated data given in Figure 1, in this case, we have four grids, two with 100 points each - Grid 2 and Grid 3. Also we have two zones:
- Zone 1: Grid 1 and Grid 2,
- Zone 2: Grid 3 and Grid 4.
In this case, we have
- ,
- ,
- , and
- .
Putting this together gives SPI = 0,
get_zone_object(grid_even, obs) |> calc_spi()
#> [1] 0Now, we consider the uneven case (Figure 2), in this case, we have the same points, 100 in Grid 3 and 100 in Grid 2, but now all the points appear in Zone 2, and none in Zone 1. So now we have
- ,
- ,
- , and
- .
plot_grid(grid_uneven, obs, grid_col = TRUE, zone_fill = TRUE)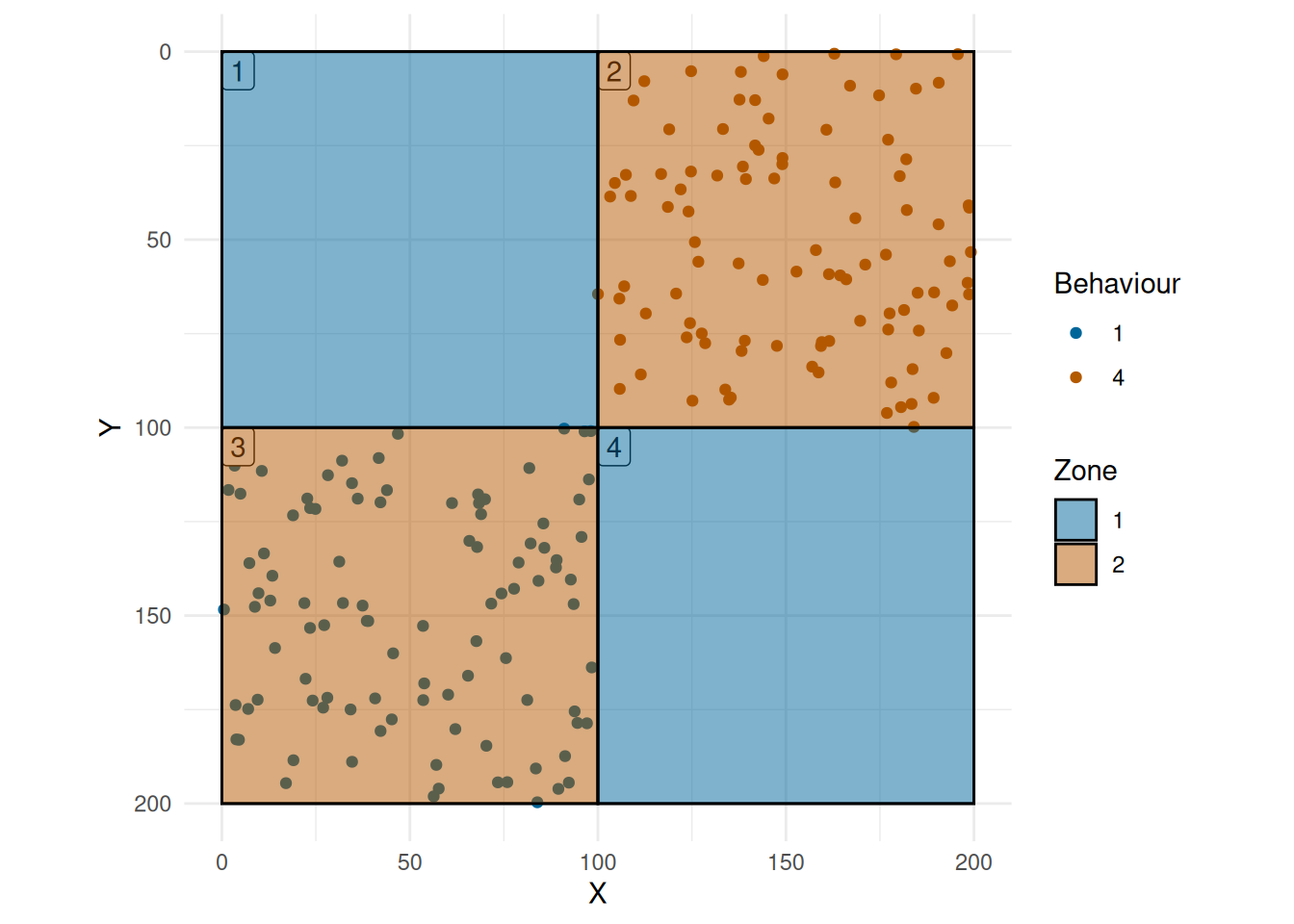
This gives the largest possible modified SPI of
get_zone_object(grid_uneven, obs) |> calc_spi()
#> [1] 1Electivity Index
From @brereton-2022, we have
where where is the number of zones, is the proportion number of observations in zone , and is the expected proportion of observations based on equal grid use.
Consider the case of even spread (Figure 1), this gives a EI of
get_zone_object(grid_even, obs) |>
calc_ei() |>
dplyr::select(zone, ei) |>
gt::gt()| zone | ei |
|---|---|
| 1 | 0 |
| 2 | 0 |
so zero for each zone. While in the case of uneven spread (Figure 2), we have an EI of
get_zone_object(grid_uneven, obs) |>
calc_ei() |>
dplyr::select(zone, ei) |>
gt::gt()| zone | ei |
|---|---|
| 1 | 0.3333333 |
| 2 | -1.0000000 |
Note that -1 indicates no use, and the 0.33 indicates sole use. The 0.33 is which goes to 1 as gets large